背景:交通出行业务场景 业务目标:拆分为用户侧和商品侧,利用用户侧用户的基本属性、社交关系和旅行状态,与商品侧做匹配,匹配的主要目的是三个方面: 需求:用算法预测用户去哪里,或者预测下阶段会去哪里 效率:首页推荐比用户搜索得到的体验更好,减少了用户看到感兴趣0D的时间。 心智:不同的用户,有不同的心智和想法,在出行中,如何捕捉到不同用户的不同心智,也就是用户的潜在心理,来引导与激发用户需求,也是一个难点。
激发需求:用户为什么想要出去? 当前热门城市,如冬季的哈尔滨、长白山等滑雪旅游城市。刘亦菲主演的《》大火后的云南大理。这些都是激发用户需求的互联网热门流行。另外节假日,如春节、国庆等固定的假日也会激发出行需求。最后就是用户自发的行为,刚好有闲时或刚好发现一个好地方。这一阶段被定义为种草,此时用户还不确定要不要出行去哪出行,平台的作用是激发并引导用户的出行需求。 行前阶段:用户已经确定要去哪里玩,那么就要确定去那个酒店、交通方式是什么,飞机还是火车,还有相应的演出及景区预约门票等,这是行前阶段。 行中阶段:用户已经到达目的地,捕获信息包括用户当点地点及心智,推荐目的在于周边有什么好玩的,回程或者下一个目标交通、酒店、门票的购买。 行程之后:用户出行后的反馈,然后再循环。
在用户出行的周期中,主要面临四个挑战: 一.决策长周期性。在传统的电商平台,例如淘宝或美团外卖,用户每个月甚至每天都会进行购物,但是旅游的决策周期非常长,一年可能只出行几次。 二.行为稀疏性。对比电商APP密集的用户行为,旅行决策的长周期性一定程度上导致了旅行场景,用户的行为序列的稀疏性。 三.行为序列性。这是旅游场景的优势。用户出行总是先通过交通工具到一个地方,定酒店住宿,再乘坐交通工具到另一个地方,用户先做什么后做什么有明显的逻辑性。我们的难点就是充分利用逻辑性。 四.时空关联性。如果用户2022年春节期间回了老家,那么其2023年春节期间也很有可能去到同一个目的地,如何捕捉时空关联性,也是一个要解决的问题。
算法 推荐算法整体上分为召回和排序两个阶段: 召回:主要有热门目的地、热门航向、Swing用户的长期需求、重定向以及用户搜索。 排序:目前线上模型主要支持单任务模型和多任务模型。 单任务学习:使用特征融合或特征交叉的AutoInt或者WDL模型,其中,用户历史典籍行为序列,采用DIN模型。 多任务学习:ESMM、MMOE、PLE等模型。
为什么要这样做? 效果如何呢? 问题的原因是什么?
有其他因素导致的伪相关,相关不等于因果,辛普森悖论 前后对比引入的干扰因素,尤其是在大互联网公司导致的 现有的序列数据处理方法大都基于RNN或CNN。
$$y_t = f(y_{t-1}, x_t) \tag{RNN}$$
RNN是一个串行的递归序列结构,本质是一个马尔科夫决策过程,无法并行,速度较慢,且无法很好得捕捉全局的结构信息(对长句子、段落来说是致命的)。
$$y_t = f(x_{t-1}, x_t,x_{t+1}) \tag{CNN}$$
CNN起源于Facebook,窗口式遍历整个向量序列,CNN方便不同于RNN,它可以并行,故而捕捉到一些全局信息。
$$y_t = f(x_{t}, A,B) \tag{Transformer}$$
Transformer,即这篇文章的主角,可以并行处理整个序列(训练耗时短),并能同等训练短期及长期依赖(对长句子也有能有效捕捉信息),并且对大数据集或有限数据集均有良好表现。由于这些优点,Transformer被使用在序列数据训练中并取得优异成绩,例如语言模型,行为序列建模中。
经过一段时间的文献阅读及研究求教,我在这里摒弃网络上里讲了一百八十遍的论文直译、高深名词和公式推导,以通俗易懂的角度来理解Transfomer的本质,它与之前的序列建模模型有什么本质区别?到底是架构中的什么在发挥作用?我们应该怎么使用它?
Transformer的本质
到底是Transformer中的什么在发挥作用?
Transformer的核心:多头自注意力机制和位置向量
多头自注意力机制Multi-Head Self-Attention
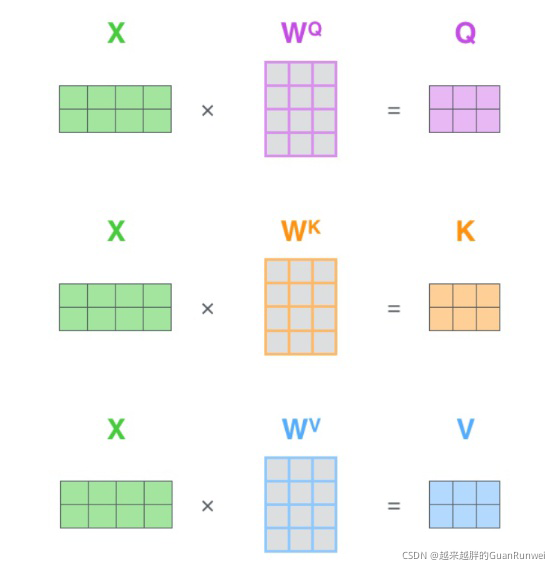
虽然Attention机制并不新鲜,但是Google在这里把Attention视作一个层看待,是一个更加正式的架构设计。 $$Attention(Q,K,V) = softmax(\frac {QK^T} {\sqrt d_k})V$$ 论文中定义了清晰的Attention公式,其中Q,K,V是三个$n*d_k、d_k*m、m*d_v$的矩阵,都是通过原序列矩阵S,与参数query,key,value相乘后得到的,Q、K、V进行上式相乘运算后得到一个$n*d_v$的矩阵,我们可以认为:这个Attention层,将序列Q($n*d_k$)编码成了一个新的$n*d_v$的序列。
想要理解这个公式,我们需要先回想一下自注意力$Softmax(SS^T)S$的含义。
首先$S·S^T$,矩阵S($n*d$)是一个item的序列,每个item都是其中的一个向量。一个矩阵乘以自己转置的运算,可以看做这些item向量分别与其他向量计算内积(第一行乘第一列、第一行乘第二列…),而向量的内积又表征了两个向量的夹角,即一个向量在另一个向量上的投影,又即两个向量的相关度。投影值越大,两个向量的相关度越大,如果两个向量夹角90°,那么这两个向量线性无关,如果夹角0°,则线性相关性最大。自然而然,这个相关性即是attention,相关性越大,需要的关注度就越大。
矩阵$\large SS^T$是一个方阵,我们以行向量的角度理解,里面保存了每个向量和自己与其他向量进行内积运算的结果。softmax就是将这些运算结果(注意力)归一化。让某个item对所有items的注意力加和值为1。
用$\large SS^T$这个权重方阵,乘原item矩阵,就得到了自注意力编码结果。

即上图中,softmax后的“早”字注意力结果为[0.4,0.4,0.2],可以理解为“早”字由0.4个“早”字,0.4个“上”字,0.2个“好”字组成。其中对“早”和“上”字的关注度比对“好”字的注意力高。经过加权加和后得到新的、编码后的“早”字item的向量。
在$Softmax(SS^T)S$的基础上,将三个S分别换成(Q,K,V),不必对(Q,K,V)感到陌生,它们都是S乘上不同的参数(query,key,value),本质上都是$\large S$的线性变换,如下图。
那么为什么不直接使用$\large X$而要对其进行线性变换呢?
当然是为了提升模型的拟合能力,矩阵$\large W$都是可以训练的,起到一个缓冲的效果。多头注意力,也是指参数矩阵$\large W$有多种组合,后将这些attention编码后的结果进行拼接。
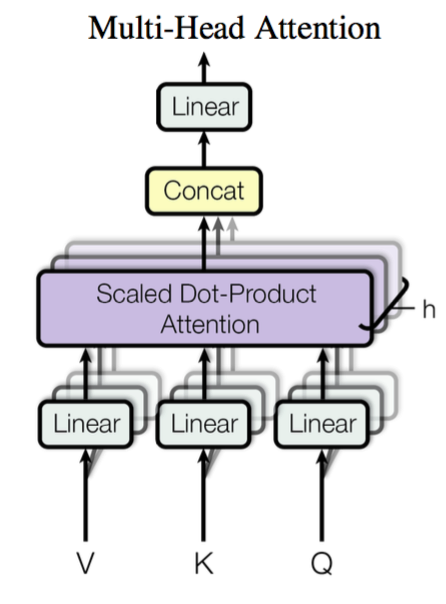
此时对于$Attention(Q,K,V) = softmax(\frac {QK^T} {\sqrt d_k})V$,我们已经理解了$softmax({QK^T})V$。
假设Q,K都服从均值为0,方差为1的标准高斯分布,那么$QK^T$中元素的均值为0,方差为d。当d变得很大时,$QK^T$中的元素的方差也会变得很大,如果QK^T$中的元素方差很大,那么$softmax(QK^T)$的分布会趋于陡峭(分布方差大,分布集中在绝对值大的区域)。总结一下就是$softmax(QK^T)$的分布会和$d$有关。因此中每个元素除以$d$后,方差又变为了1。这使得的分布的陡峭程度和$d$成功解耦,从而使得Transformer在训练过程中的梯度值保持稳定。总的来说,d的维度就是$QK^T$的维度,除以d的目的就是降低方差。
而在NLP中,我们需要不同的模式识别。比如第一个head用来识别词语间的指代关系(某个句子里有一个单词it,这个it具体指什么呢),第二个head用于识别词语间的时态关系(看见yesterday就要用过去式)等等,来捕捉单词之间多种维度上的相关系数 attention score,将每个head(维度)上的相关系数分数打出,可以具象化地感受每个head的关注点,以句子"The animal didn’t cross the streest because it was too tired"为例。

设头的数量为num_heads,那么本质上,就是训练num_heads个$W_Q,W_K,W_V$ 个矩阵,用于生成num_heads个 Q,K,V 结果。每个结果的计算方式和单头的attention的计算方式一致,最后将多个头的结果concat起来。值得注意的是,为了使多头的结果维度不受影响且运算量不增加,$W_Q,W_K,W_V$的维度要相应变小为d_model//num_heads。
位置编码Position Embedding
最开始介绍模型的时候,我们提到过,Transformer只需要自注意力就可以捕捉序列信息,可上一部分讨论的自注意力机制只根据每个item自身的Embedding编码来计算注意力,即只是个精妙的“词袋模型”而已!它并不能捕捉item的前后顺序信息。举个例子,就算把句子中的词都打乱顺序,得到的结果还是一样的。
那Transformer是通过什么来学习顺序信息的呢?那就是Position Embedding,位置向量,将每个位置编号,然后每个编号对应一个向量,通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了,可以看到下图中,位置编码被应用于增强模型输入,让输入的词向量具有它的位置信息,是一个相对独立的模块。
说到位置编码,其实Facebook的CNN序列模型中就有过应用,但在CNN与RNN模型中,位置编码比较粗糙,因为RNN和CNN本就可以捕捉到位置信息,所以位置编码的作用并不突出。但在Transformer中,位置编码是位置信息的唯一来源,是整个模型的核心成分,论文也对其做了更详细的研究和描述。
一种好的位置编码方案需要满足以下几条要求:
它能为每个时间步输出一个独一无二的编码; 不同长度的句子之间,任何两个时间步之间的距离应该保持一致; 模型应该能毫不费力地泛化到更长的句子。它的值应该是有界的; 它必须是确定性的;
这样它才能用来表征item的绝对关系和相对关系。以往的Position Embedding中,基本都是根据任务训练出来的向量。而Google直接给出了一个构造Position Embedding的公式:
这种编码不是单一的数值,而是包含句子中特定位置信息的[公式]维向量(非常像词向量)。PE是一个矩阵[句子长度,模型隐层维度(BERT base中取768)],其中矩阵的每一行都是对应词的位置向量,位置向量长度为模型隐层维度,之后会与输入词向量进行相加(直接相加的原因请看下一章)。下面就是PE这个矩阵的计算方法。
$$\begin{cases} PE(pos,2i) = sin(pos/10000^{2i/d_{model}})\ PE(pos,2i+1) = cos(pos/10000^{2i/d_{model}}) \end{cases}$$
其中pos为token在序列中的位置号码,它的取值是0到序列最大长度之间的整数。BERT base最大长度是512,pos取值能一直取到511。当然如果序列真实长度小于最大长度时,后面的位置号没有意义,最终会被mask掉。
$d_{model}$是位置向量的维度,与整个模型的隐藏状态维度值相同,即嵌入向量的维度,这个维度在bert base模型里设置为768。
$i$ 是从0到$d_{model}/2-1$之间的整数值,即0,1,2,…383。
$2i$ 是指向量维度中偶数维,即第0维,第2维,第4维,直到第766维。
$2i+1$ 是维度中奇数维,即第1维,第3维,第5维,直到第767维。
PE(pos,2i)是PE矩阵中第pos行,第2i列的数值,是个标量。这里是在第偶数列上的值,偶数列用正玄函数计算。
PE(pos,2i+1) 是PE矩阵中第pos行,第2i+1列的数值,是个标量。这里是在第奇数列上的值,奇数列用余玄函数计算。
由于三角函数是周期函数,随着位置号的增加,相同维度的值有周期性变化的特点。同样对于两个长度相同的句子,它们的位置编码完全一样。
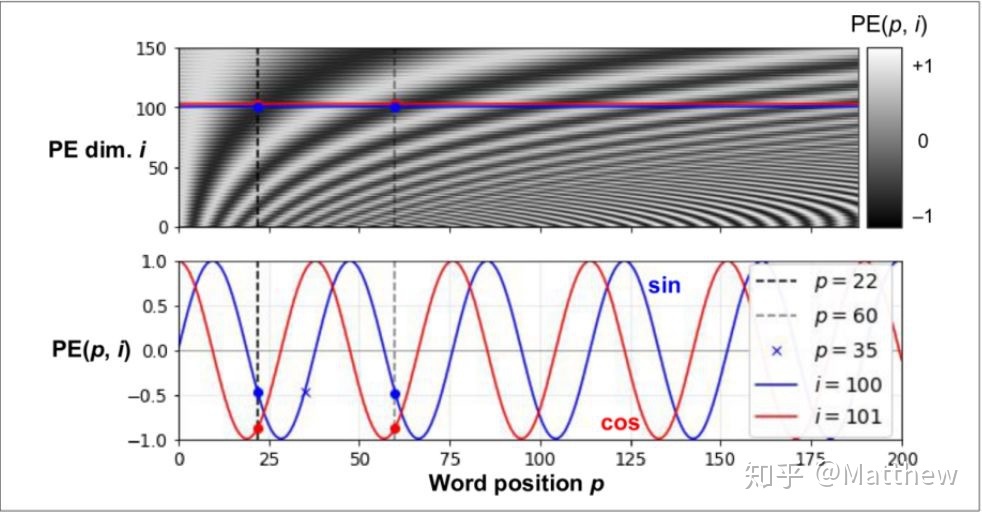
为什么要使用sin和cos值呢,因为相对绝对位置,相对位置更重要,而三角函数的性质: $$sin(α+β) = sinαcosβ + cosαsinβ$$ $$cos(α+β) = cosαcosβ - sinαsinβ$$
因此可以推导出,两个位置向量的点积是一个与他们两个位置差值(即相对位置)有关,而与绝对位置无关。这个性质使得在计算注意力权重的时候(两个向量做点积),使得相对位置对注意力发生影响,而绝对位置变化不会对注意力有任何影响,这更符合常理。但是这里似乎有个缺陷,就是这个相对位置没有正负之分,比如"华"在"中"的后面,对于"中"字,“华"相对位置值应该是1,而"爱"在"中"的前面,相对位置仍然是1,这就没法区分到底是前面的还是后面的。
Google在论文中说到他们比较过直接训练出来的位置向量和上述公式计算出来的位置向量,效果是接近的,所以可以直接使用,无需再耗费算力训练位置向量,毕竟Attention自身的复杂度也是比较高的。
注:在bert的代码中采用的是可训练向量方式。
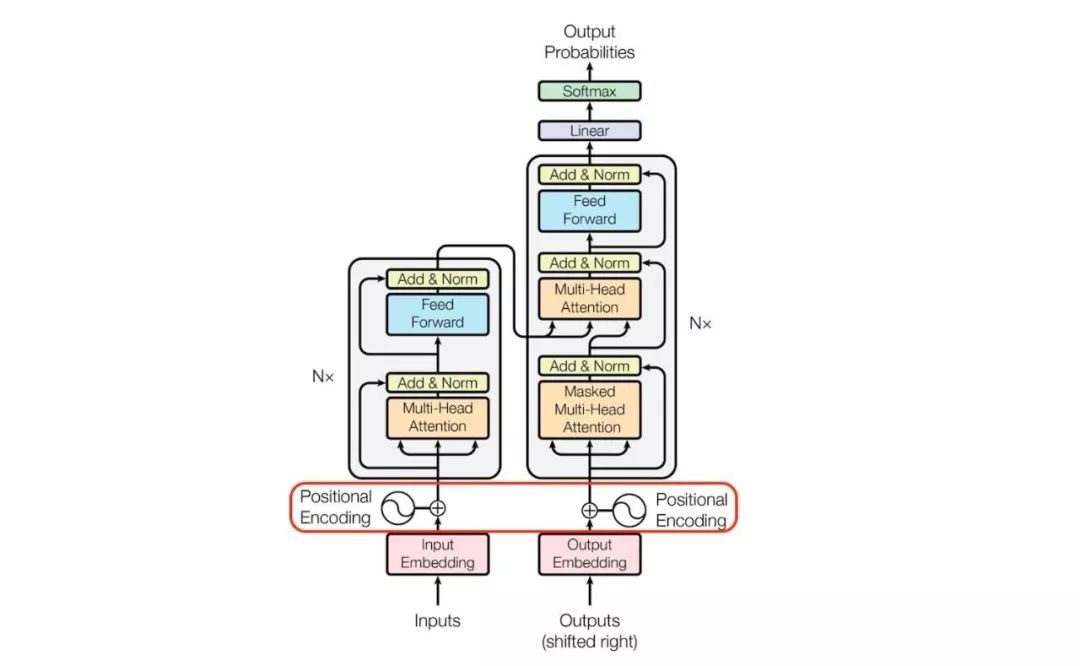
Transformer架构
Encoder-Decoder
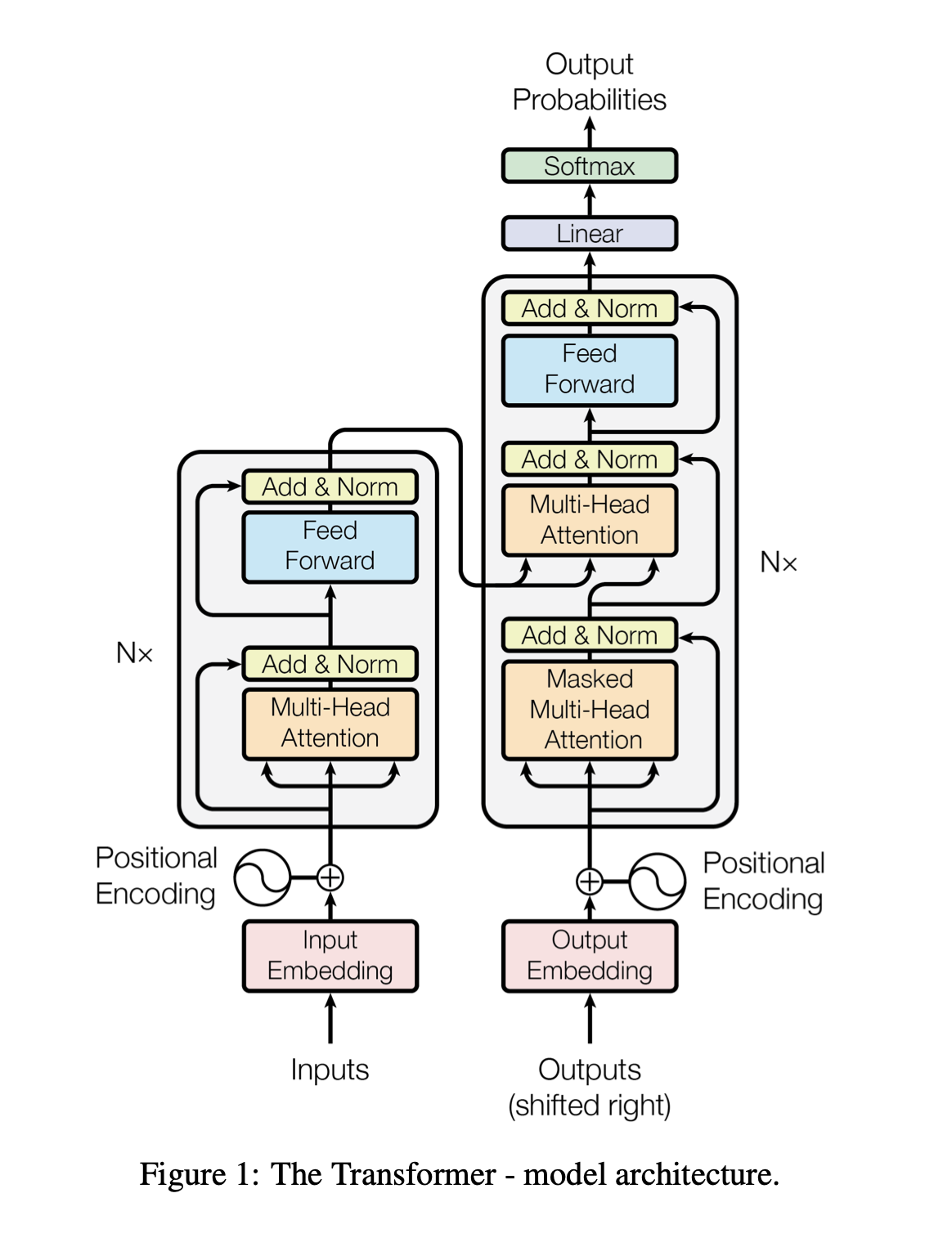
其中Encoder部分应用比较多,例如BERT中使用了Encoder部分进行预训练,行为序列建模也只使用了Encoder部分。
Encoder
Encoder是将输入重编码的一个过程,输入$X_{Embedding}$[batch size, sequence length, embedding dimention],输出相同shape的$X_{hidden}$[batch size, sequence length, embedding dimention]
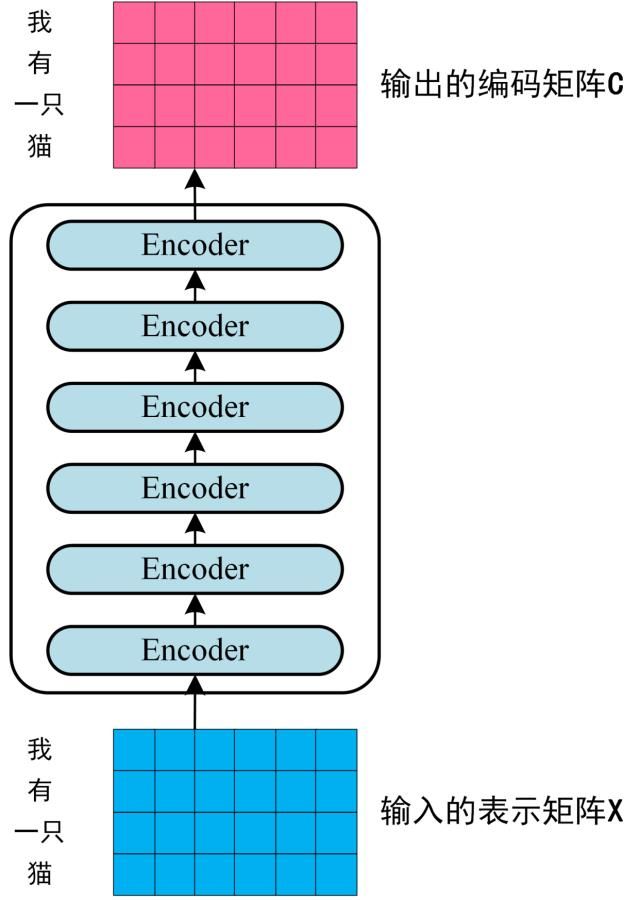
从Input开始,通过查表进行Embedding,此时输入$X_{Embedding}$[batch size, sequence length, embedding dimention] (论文中embedding dimention d_model = 512)
$X_{Embedding}$流转到Positional Encoding,按照上文的正余弦计算公式,计算sequence中的位置向量矩阵$X_{pos}$,并进行相加(为何直接进行相加,而不是concat,后文会探讨)$X_{Embedding}=X_{Embedding}+X_{pos}$,为了可以相加,pos的shape要于embedding的完全相同,即[batch size, sequence length, embedding dimention]
此时加入位置信息的$X_{Embedding}$进入了重头戏–自注意力,将$X_{Embedding}$乘不同的权重矩阵$W_Q,W_K,W_V$进行线性映射产生Q,K,V。Key就是键用来和你要查询的Query做比较,比较得到一个分数(相关性或者相似度)再乘以Value这个值得到最终的结果。多头就是多个上述attention模块(参数不共享),以此增加泛化能力,最后将所有的结果concat,由于权重矩阵$W_Q,W_K,W_V$根据头数进行压缩d_model//num_heads,此时$X_{hidden}$维度仍为[batch size, sequence length, embedding dimention]
Add & Norm这一步进行了残差连接和Layer Normalization。残差连接就是把输入$X_{Embedding}$和多头自注意力的输出连接起来,即$X_{Embedding}+Attention(Q,K,V)$,此时输出维度为[batch size, sequence length, embedding dimention]。Layer Normalization作用是把神经网络中隐藏层归一为标准正态分布,加速收敛,具体操作是将每一行的每个元素减去这行的均值,再除以这行的标准差,从而得到归一化后的数值。
上述归一化后的结果[batch size, sequence length, embedding dimention]输入前馈网络,简单的两层线性映射再经过激活函数一下,即$X_{hidden} = Relu(X_{hidden}W_1W_2)$,后再进行一遍上述的Add & Norm操作。
Decoder
Decoder类似于RNN,是一个item间串行的过程。
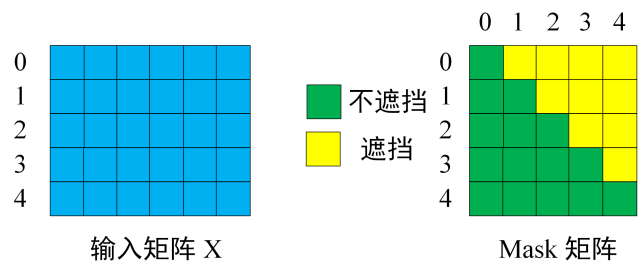
将Encoder 输出的编码信息矩阵C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。注意Mask 操作是在 Self-Attention 的 Softmax 之前使用的,下面用 0 1 2 3 4 5 分别表示 “ I have a cat "。

上图 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 “",预测第一个单词 “I”;然后输入翻译开始符 “” 和单词 “I”,预测单词 “have”,以此类推。这是 Transformer 使用时候的大致流程,接下来是里面各个部分的细节。
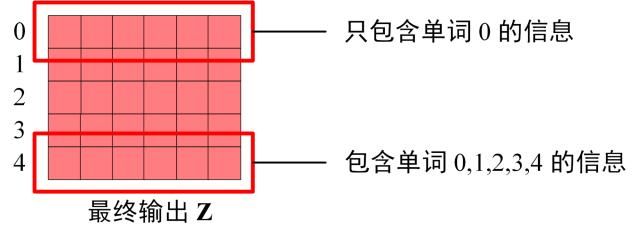
第一步:是 Decoder 的输入矩阵和 Mask 矩阵,输入矩阵包含 “ I have a cat” (0, 1, 2, 3, 4) 五个单词的表示向量,Mask 是一个 5×5 的矩阵。在 Mask 可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息。
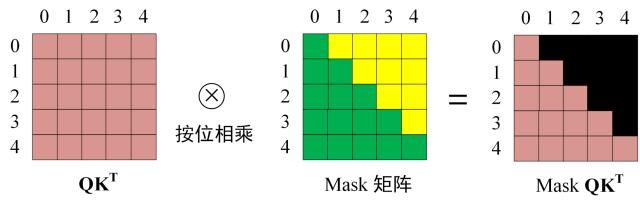
第二步–Masked Multi-Head Attention:接下来的操作和之前的 Self-Attention 一样,通过输入矩阵X计算得到Q,K,V矩阵。不同的是在$QK^T$后,需要按位乘Mask矩阵,以遮挡每个单词之后的信息,然后才能乘$V$。
第三步–Multi-Head Attention:第二个多头注意力,主要特点为K,V矩阵来自Encoder的编码矩阵C,而只有Q来自decoder上一步的输出Z,这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。
第四步–预测:
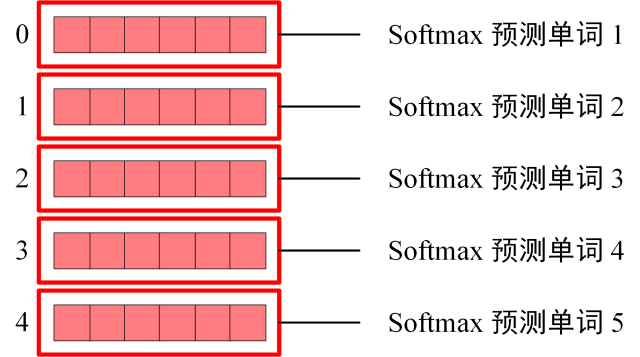
Decoder block 最后的部分是利用 Softmax 预测下一个单词,在之前的网络层我们可以得到一个最终的输出 Z,因为 Mask 的存在,使得单词 0 的输出 Z0 只包含单词 0 的信息,输入Z如下:
Softmax 根据Z的每一行预测下一个单词:
要注意的是,这是训练的时候,可以通过mask直接并行输入整个句子,推理时还是要串行训练的。
Transformer与其他序列建模模型的区别
Transformer好在哪?是哪些特质让它拥有这些优点?它有没有相对于其他模型的缺点?
优点
-
可以直接计算每个词之间的相关性,不需要通过隐藏层传递
-
可以并行计算,可以充分利用GPU资源
这里的并行指的不是很多seq形成的batch同时运行,而是模型本身对单个seq输入训练/推理时的并行能力。Encoder部分不用说,因为position embedding的引入,无需再像RNN一样逐个item计算。对于Decoder端,做推理的时候类似RNN, 是很难并行的. 但是训练的时候可以一口气把整个seq输入进去,通过mask做后续遮掩,做到类似encoder部分的并行。
Transformer要怎么用
BST模型是阿里搜索推荐团队2019年发布在arXiv上的文章《Behavior Sequence Transformer for E-commerce Recommendation in Alibaba》。核心为使用Transformer捕捉用户行为序列的序列信息。目前BST已经部署在淘宝推荐的精排阶段,每天为数亿消费者提供推荐服务。
对于用户行为序列(UBS:User Behaviour Sequence)的信息捕捉,已有的UBS的建模方式可以归纳为:
1.sum/mean pooling,工业实践中的效果还不错 2.weight pooling,关键点是weight的计算方式。例如经典模型DIN,DIN使用注意力机制来捕捉候选item与用户点击item序列之间的相似性作为weight 3.RNN类,考虑时序信息,例如阿里妈妈利用GRU捕捉USB序列信息,将DIN升级为DIEN。这是一种非常大的突破,因为在推荐中首次考虑了购买序列的前后时序,即“未来”的信息,例如买了手机的用户,下一刻可能会购买耳机、保护膜。
随着Transformer在很多NLP任务中的表现超过RNN,相比RNN也有可并行的独特优势,利用Transformer代替RNN来捕捉时序信息是个很自然的想法,BST就应运而生了。其中的核心创新点就是使用Transformer来建模输入特征中的时序特征。
结构如下:
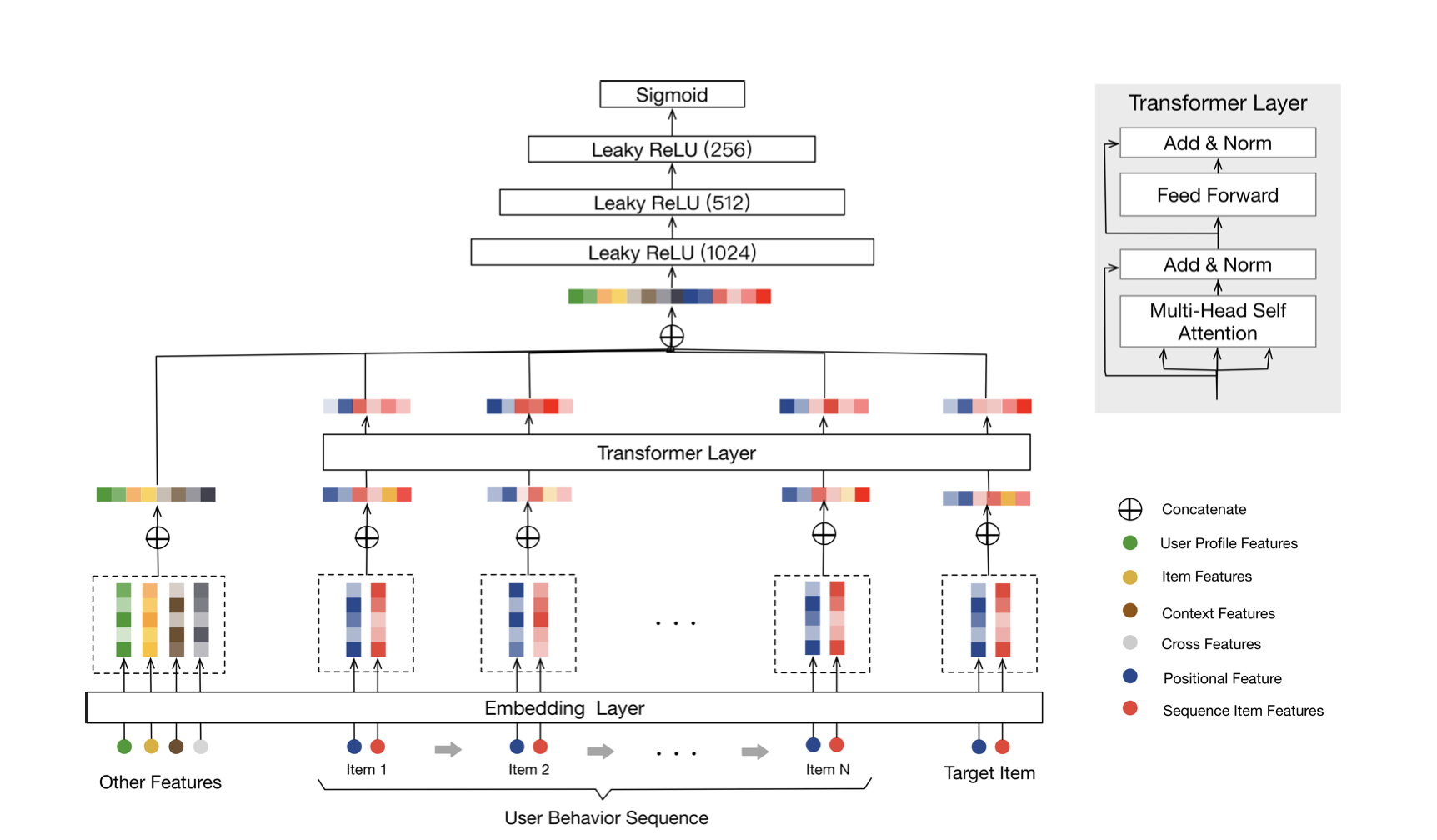
BST符合CTR中典型的 MLP+Embedding 结构,核心在图中右半部分,即使用 Transformer Layer 建模 User Behavior Sequence。
Transformer的原理已经讲述过了,这里使用的就是encoder部分将行为矩阵映射为另一个矩阵,需要补充的是,论文中使用的行为长度为20,即截断取用户最近的N个行为,若用户少于N个行为则直接padding补零向量,DIEN中最长使用50长度。embedding size中在4~64之间。
Transformer其他思考
为什么输入向量可以直接相加 https://www.zhihu.com/question/374835153
多头注意力中,并无法每个头都平均准确得关注不同的点,只有几个头是重要的,可以进行剪枝 https://www.zhihu.com/question/341222779